Zazwyczaj unikam rozmów na temat wyższości jednego języka (programowania) nad drugim. Głównie ze względu na to, że każdy programista ma jakiś swój ulubiony język i przy takiej dyskusji stosuje bardziej emocjonalne argumenty niż rzeczowe. Niestety ostatnio zostałem w taką dyskusję wciągnięty.
Człowiek, z którym rozmawiałem jest ewidentnym zwolennikiem programowania w C# pod platformą Windows. I tak jak się obawiałem pytania, które padały były emocjonalne (tzn. nie za bardzo dotyczyły tematu rozmowy). Na przykład ów człowiek zapytał mnie - niby całkiem rzeczowo - dlaczego warto programować w Haskellu. Dodam jeszcze, że on o tym języku w ogóle nie słyszał. Pytanie byłoby jak najbardziej na miejscu, gdyby nie dalsza część, którą dopowiedział chwilę później, a mianowicie jak została rozwiązana komunikacja z maszyną wirtualną od C# i czy komunikacja z Windowsem odbywa się za pomocą obiektów COM+.
Widać zatem, że pytanie w całości nie dotyczyło w ogóle cech języka programowania tylko raczej sposobu w jakim zostały napisane biblioteki. Ewidentnie oczekiwał on odpowiedzi, która wyraziłaby wyższość C# nad Haskellem, ponieważ komunikacja z Windowsem jest bardziej efektywna w C#. To przypomina mi bardzo pytanie o to co da się w danym języku napisać. Odpowiedź brzmi wszystko, w tym również da się napisać efektywną komunikację z Windowsem ale to nigdy nie powinno dotyczyć porównywania języków programowania (co najwyżej środowisk programistycznych lub wsparcia). Na marginesie dodam, że jeśli nawet w Haskellu nie da się napisać szybko działającej jakiejś krytycznej części programu to zawsze można to napisać chociażby w C, z którym Haskell świetnie się integruję (za pomocą modułu FFI).
Moim skromnym zdaniem takie rozmowy powinny dotyczyć zalet elementów składniowych języka a nie możliwości jego bibliotek. Wiem, że większość programistów uważa, że dzisiaj język bez dobrego zaplecza w postaci ogromu bibliotek i najlepiej jakiejś firmy (korporacji), która za tym stoi jest nic nie wart. Ja jednak na takie zarzuty odpowiadam, że w przypadku gdy w jednym języku nie ma napisanej danej funkcjonalności a w drugim jest to faktycznie ten drugi wypada lepiej. Jednak jeśli danej funkcjonalności nie ma ani tu ani tu to wygrywa język, w którym piszę się szybciej, krócej i poprawniej.
Na dłuższą metę koszt poniesiony na początku w postaci napisania funkcjonalności bardzo szybko się zwróci w przypadku takich właśnie języków. To tak jak z algorytmami działającymi lepiej gdy dane są posortowane - sortowanie danych faktycznie zajmuje trochę czasu ale gdy dane są odpowiednio duże (czyli w naszym przypadku program) to nie ma on żadnego znaczenia a czas działania algorytmu znacząco się skraca.
poniedziałek, 28 listopada 2011
poniedziałek, 21 listopada 2011
UML a Haskell
Dzisiaj chciałbym poruszyć temat projektowania aplikacji haskellowych przy użyciu UMLa. Zajmę się tylko diagramem klas, gdyż akurat ostatnio próbowałem się z nim zmierzyć (w kontekście aplikacji haskellowych). Aby jednak zacząć w ogóle mówić o diagramie klas musiałbym pokrótce omówić typy danych jakie występują w Haskellu oraz ich podobieństwa do typów używanych w językach imperatywnych orientowanych obiektowo jak np. C++ czy Java.
W Haskellu rozróżniamy głównie 2 słowa kluczowe służące do tworzenia typów: class oraz data (istnieje również type, który tworzy tylko alias do typu oraz newtype, który jest raczej zabiegiem optymalizacyjnym). Oczywiście w językach funkcyjnych również funkcja jest typem danych. Omówię teraz z grubsza wyżej wymienione słowa kluczowe. Zapisy tłumaczył będę imperatywnie, tzn. używając słów takich jak chociażby interfejs, które oczywiście nie występują w Haskellu.
Tłumacząc to na język imperatywny powiedzielibyśmy, że Foo jest klasą, która zawiera atrybut o nazwie fooname typu String oraz metodę o nazwie foofunction, która przyjmuje obiekt typu Int jako argument i zwraca obiekt typu String. Jak zatem tworzymy instancję klasy? Ano tak:
Pierwsza różnica jaką widać w stosunku do języków imperatywnych to fakt, że możemy przyjąć funkcję jako argument konstruktora. Oczywiście w językach typu C-podobnych moglibyśmy wykorzystać w tym celu wskaźnik do funkcji bądź delegaty. Rozważmy zatem nieco bardziej wyrafinowany typ:
Zmieniła się definicja foofunction. Moglibyśmy przeczytać ją następująco: foofunction jest funkcją, która przyjmuje argument dowolnego typu i zwraca obiekt typu String. Aby wyrazić taką funkcję w imperatywnych językach potrzebny jest jakiś mechanizm template'ów. OK, a co powiedzie na taki typ:
Teraz foofunction jest funkcją, która przyjmuje argument dowolnego typu, który implementuje interfejs Show i zwraca obiekt typu String. W Javie po prostu funkcja ta przyjmowałaby jako argument ten interfejs a raczej "obiekt interfejsu". No dobrze, a co w takim przypadku:
W tym przypadku foofunction jest funkcją, która przyjmuje argument dowolnego typu, który implementuje interfejs Show oraz interfejs Ord i zwraca obiekt typu String. Teraz jest znacznie ciężej wyrazić to w Javie. Trzeba by utworzyć osobny typ (klasę), który implementuje te interfejsy i użyć go jako argument funkcji.
Typy tworzone przez data mogą być również parametryzowane:
Obiekt tworzylibyśmy w ten sposób:
Natomiast obiekt takiej klasy przyjmowalibyśmy w funkcji np. w taki sposób:
Pierwsza funkcja jest polimorficzna czyli zadziała dla każdego typu Foo3, a druga tylko dla typu Foo3 Int.
Jak widać jest to prosty interfejs z metodą show, która przyjmuje argument typu a i zwraca obiekt typu String. Jest to tylko deklaracja typu funkcji bez jej ciała. Jak widać również tutaj w przypadku języków imperatywnych trzeba by zastosować mechanizm template'ów. Jak zatem implementuje się ten interfejs? A tak:
W tym momencie na dowolnym obiekcie klasy Foo możemy wywołać funkcję show i zawsze w wyniku otrzymamy napis Foo. Pominę może aspekt, że metody/atrybuty w interfejsach mogą przyjmować domyślne definicje co różni je od interfejsów w Javie.
Podstawy za nami więc pora na bardziej skomplikowany typ:
Ten zapis powoduje, że implementować interfejs Show mogą klasy, które implementują już interfejs Ord. Czy da się coś takiego wyrazić w językach imperatywnych? Ja nie znam żadnej konstrukcji ale też żadnym mistrzem w C++ czy Javie nie jestem więc jak ktoś wie jak można to zrobić to proszę niech napisze w komentarzu.
To nie jedyne różnice. Pokażmy zatem coś znacznie ciekawszego:
Zapis po kresce oznacza, że typ e jest jednoznacznie określony przez typ c. Co to oznacza? Oznacza to tyle, że jak istniała by instancja powiedzmy Collection Array Int to nie może istnieć inna klasa implementująca ten interfejs taka, że c będzie typu Array, a e NIE będzie typu Int.
Nie dodałem tu jeszcze, że interfejsy mogą implementować typy polimorficzne takie jak chociażby lista elementów dowolnego typu: [a]. Czyli taki zapis:
w tym przypadku oznacza, że "[a] a" jest kolekcją i żadna inna kolekcja "zaczynająca się" od [a] istnieć nie może. Oznacza on również, że "[Int] Int" jest kolekcją oraz że "[Char] Char" jest kolekcją itd. Tak na marginesie to widać tu jeszcze jedną rzecz, której nie da się (chyba) wyrazić w wymienionych językach imperatywnych, tzn. "[a] a" - jak pierwszy typ będzie powiedzmy [Int] to drugi musi być Int (ponieważ a jest typu Int).
Czego zatem użyć zamiast diagramu klas skoro się nie nadaje? W UMLu nie ma moim zdaniem odpowiedniego diagramu. Pewien człowiek napisał propozycję diagramów do projektowania funkcyjnego w swoim doktoracie: link. Większość ludzi jednak uważa, że w przypadku nie zbyt dużych programów wystarczy pisać program w odpowiedni sposób, który Haskell akurat wymusza. Jaki to konkretnie sposób? Odsyłam do książki "Real World Haskell". W przypadku większych aplikacji polecam użyć jakiegoś prostego programu do tworzenia diagramów chociażby jak CmapTools. Tyle, że sami musimy ustalić sobie jak ma być prezentowana klasa, jak interfejs a jak funkcja itd. Niestety kodu nam to nie wygeneruje ale aplikację uda się z powodzeniem zaprojektować.
W Haskellu rozróżniamy głównie 2 słowa kluczowe służące do tworzenia typów: class oraz data (istnieje również type, który tworzy tylko alias do typu oraz newtype, który jest raczej zabiegiem optymalizacyjnym). Oczywiście w językach funkcyjnych również funkcja jest typem danych. Omówię teraz z grubsza wyżej wymienione słowa kluczowe. Zapisy tłumaczył będę imperatywnie, tzn. używając słów takich jak chociażby interfejs, które oczywiście nie występują w Haskellu.
data
Zacznę o słówka data, ponieważ jest ono mniej abstrakcyjne od class. Typy tworzone przez właśnie to słowo odpowiadają klasą znanym z języków obiektowych. Wygląda to mniej więcej tak:data Foo = Foo { fooname :: String, foofunction :: Int -> String }
Tłumacząc to na język imperatywny powiedzielibyśmy, że Foo jest klasą, która zawiera atrybut o nazwie fooname typu String oraz metodę o nazwie foofunction, która przyjmuje obiekt typu Int jako argument i zwraca obiekt typu String. Jak zatem tworzymy instancję klasy? Ano tak:
fooInstance :: Foo fooInstance = Foo "foo" (\a -> "foo: " ++ (show a))
Pierwsza różnica jaką widać w stosunku do języków imperatywnych to fakt, że możemy przyjąć funkcję jako argument konstruktora. Oczywiście w językach typu C-podobnych moglibyśmy wykorzystać w tym celu wskaźnik do funkcji bądź delegaty. Rozważmy zatem nieco bardziej wyrafinowany typ:
data Foo2 = Foo2 { fooname :: String, foofunction :: a -> String }
Zmieniła się definicja foofunction. Moglibyśmy przeczytać ją następująco: foofunction jest funkcją, która przyjmuje argument dowolnego typu i zwraca obiekt typu String. Aby wyrazić taką funkcję w imperatywnych językach potrzebny jest jakiś mechanizm template'ów. OK, a co powiedzie na taki typ:
data Foo3 = Foo3 { fooname :: String, foofunction :: (Show a) => a -> String }
Teraz foofunction jest funkcją, która przyjmuje argument dowolnego typu, który implementuje interfejs Show i zwraca obiekt typu String. W Javie po prostu funkcja ta przyjmowałaby jako argument ten interfejs a raczej "obiekt interfejsu". No dobrze, a co w takim przypadku:
data Foo3 = Foo3 { fooname :: String, foofunction :: (Show a, Ord a) => a -> String }
W tym przypadku foofunction jest funkcją, która przyjmuje argument dowolnego typu, który implementuje interfejs Show oraz interfejs Ord i zwraca obiekt typu String. Teraz jest znacznie ciężej wyrazić to w Javie. Trzeba by utworzyć osobny typ (klasę), który implementuje te interfejsy i użyć go jako argument funkcji.
Typy tworzone przez data mogą być również parametryzowane:
data Foo3 b = FooB { fooid :: (Show b) => b, foofunction :: (Show a, Ord a) => a -> String }
Obiekt tworzylibyśmy w ten sposób:
fooInstance :: Foo3 Int fooInstance = FooB 3 (\a -> "foo: " ++ (show a))
Natomiast obiekt takiej klasy przyjmowalibyśmy w funkcji np. w taki sposób:
fooFun :: Foo3 b -> b fooFun foo = fooid foo fooFunSpec :: Foo3 Int -> Int fooFunSpec = fooid foo
Pierwsza funkcja jest polimorficzna czyli zadziała dla każdego typu Foo3, a druga tylko dla typu Foo3 Int.
class
Klasy w Haskellu nie są tym samym co klasy w Javie czy w C++. Przypominają one raczej interfejsy znane z Javy tylko znacznie lepsze. Prosty przykład:class Show a where
show :: a -> String
Jak widać jest to prosty interfejs z metodą show, która przyjmuje argument typu a i zwraca obiekt typu String. Jest to tylko deklaracja typu funkcji bez jej ciała. Jak widać również tutaj w przypadku języków imperatywnych trzeba by zastosować mechanizm template'ów. Jak zatem implementuje się ten interfejs? A tak:
instance Show Foo where
show _ = "Foo"
W tym momencie na dowolnym obiekcie klasy Foo możemy wywołać funkcję show i zawsze w wyniku otrzymamy napis Foo. Pominę może aspekt, że metody/atrybuty w interfejsach mogą przyjmować domyślne definicje co różni je od interfejsów w Javie.
Podstawy za nami więc pora na bardziej skomplikowany typ:
class (Ord a) => Show a where
show :: a -> String
Ten zapis powoduje, że implementować interfejs Show mogą klasy, które implementują już interfejs Ord. Czy da się coś takiego wyrazić w językach imperatywnych? Ja nie znam żadnej konstrukcji ale też żadnym mistrzem w C++ czy Javie nie jestem więc jak ktoś wie jak można to zrobić to proszę niech napisze w komentarzu.
To nie jedyne różnice. Pokażmy zatem coś znacznie ciekawszego:
class Eq e => Collection c e | c -> e where
...
Zapis po kresce oznacza, że typ e jest jednoznacznie określony przez typ c. Co to oznacza? Oznacza to tyle, że jak istniała by instancja powiedzmy Collection Array Int to nie może istnieć inna klasa implementująca ten interfejs taka, że c będzie typu Array, a e NIE będzie typu Int.
Nie dodałem tu jeszcze, że interfejsy mogą implementować typy polimorficzne takie jak chociażby lista elementów dowolnego typu: [a]. Czyli taki zapis:
instance Collection [a] a where
...
w tym przypadku oznacza, że "[a] a" jest kolekcją i żadna inna kolekcja "zaczynająca się" od [a] istnieć nie może. Oznacza on również, że "[Int] Int" jest kolekcją oraz że "[Char] Char" jest kolekcją itd. Tak na marginesie to widać tu jeszcze jedną rzecz, której nie da się (chyba) wyrazić w wymienionych językach imperatywnych, tzn. "[a] a" - jak pierwszy typ będzie powiedzmy [Int] to drugi musi być Int (ponieważ a jest typu Int).
UML
Powróćmy zatem do UMLa. O ile typy tworzone za pomocą słówka data i relacje między nimi da się jakoś na siłę wyrazić na diagramie klas o tyle już w przypadku słówka class nie za bardzo. No bo jak ma z diagramu wynikać, że np. klasa (słówko data) "Article a" ma być taka, że a implementuje interfejs (słówko class) Foo, a do tego interfejs Foo mogą implementować tylko te klasy, które implementują jeszcze interfejs Show oraz interfejs Ord? Nie mówiąc już o funkcjach istniejących poza interfejsami/klasami.Czego zatem użyć zamiast diagramu klas skoro się nie nadaje? W UMLu nie ma moim zdaniem odpowiedniego diagramu. Pewien człowiek napisał propozycję diagramów do projektowania funkcyjnego w swoim doktoracie: link. Większość ludzi jednak uważa, że w przypadku nie zbyt dużych programów wystarczy pisać program w odpowiedni sposób, który Haskell akurat wymusza. Jaki to konkretnie sposób? Odsyłam do książki "Real World Haskell". W przypadku większych aplikacji polecam użyć jakiegoś prostego programu do tworzenia diagramów chociażby jak CmapTools. Tyle, że sami musimy ustalić sobie jak ma być prezentowana klasa, jak interfejs a jak funkcja itd. Niestety kodu nam to nie wygeneruje ale aplikację uda się z powodzeniem zaprojektować.
wtorek, 15 listopada 2011
Multikolorowanie grafu w Haskellu
Ostatnio na studiach dostałem takie zadanie do zaimplementowania:
Część I:
Wygenerować plik w formacie GXL zawierający graf składający się ze stacji, które są losowe rozmieszczone wewnątrz miasta, w którym stacje są połączone krawędzią wtedy, gdy ich zasięg się pokrywa.
Wejście:
Wyjście:
Uzyskany graf w formacie GXL.
Część II
Należy wczytać wygenerowany wcześniej graf oraz zapotrzebowanie na częstotliwości dla każdej stacji. Stacje, których zasięg się pokrywa nie mogą uzyskać tych samych częstotliwości. Program powinien znaleźć jak najmniejszą liczbę różnych częstotliwości potrzebnych aby stacje mogły funkcjonować.
Przykład:
Mając prosty graf [1]->[2]->[3] i wiedząc, że stacja 1 potrzebuje 3 częstotliwości, stacja 2 potrzebuje 4 a stacja ostatnia 5. Wówczas powinniśmy przydzielić częstotliwości np. tak:
Wejście:
Wyjście:
Problem postanowiłem rozwiązać w Haskellu z uwagi na możliwość operacji na listach nieskończonych co w tym przypadku bardzo ułatwia znajdowanie częstotliwości. W części II wykorzystałem algorytm SLF. Oczywiście problem jest NP zupełny więc nie ma idealnego algorytmu, który by przydzielił zawsze najmniejszą możliwą do uzyskania liczbę częstotliwości dla każdego przypadku.
Część I: gxl.hs
Część II: multicolor.hs
Plik do obsługi formatu GXL (wymagany aby skompilować poprzednie 2 pliki): gxl_dtd.hs
Część I:
Wygenerować plik w formacie GXL zawierający graf składający się ze stacji, które są losowe rozmieszczone wewnątrz miasta, w którym stacje są połączone krawędzią wtedy, gdy ich zasięg się pokrywa.
Wejście:
- Współrzędne środka koła (miasta)
- Promień koła (miasta)
- Liczba stacji
- Zasięg (promień) stacji
Wyjście:
Uzyskany graf w formacie GXL.
Część II
Należy wczytać wygenerowany wcześniej graf oraz zapotrzebowanie na częstotliwości dla każdej stacji. Stacje, których zasięg się pokrywa nie mogą uzyskać tych samych częstotliwości. Program powinien znaleźć jak najmniejszą liczbę różnych częstotliwości potrzebnych aby stacje mogły funkcjonować.
Przykład:
Mając prosty graf [1]->[2]->[3] i wiedząc, że stacja 1 potrzebuje 3 częstotliwości, stacja 2 potrzebuje 4 a stacja ostatnia 5. Wówczas powinniśmy przydzielić częstotliwości np. tak:
- Stacja nr 1: 4,5,6
- Stacja nr 2: 0,1,2,3
- Stacja nr 3: 4,5,6,7,8
Wejście:
- Plik GXL
- Zapotrzebowanie na częstotliwości dla każdej stacji
Wyjście:
- Liczba przydzielonych różnych częstotliwości
Problem postanowiłem rozwiązać w Haskellu z uwagi na możliwość operacji na listach nieskończonych co w tym przypadku bardzo ułatwia znajdowanie częstotliwości. W części II wykorzystałem algorytm SLF. Oczywiście problem jest NP zupełny więc nie ma idealnego algorytmu, który by przydzielił zawsze najmniejszą możliwą do uzyskania liczbę częstotliwości dla każdego przypadku.
Część I: gxl.hs
Część II: multicolor.hs
Plik do obsługi formatu GXL (wymagany aby skompilować poprzednie 2 pliki): gxl_dtd.hs
niedziela, 13 listopada 2011
Leniwa potęga
Dla odmiany dzisiaj napiszę o Haskellu. Poznałem ten język stosunkowo niedawno (jakieś 1,5 roku temu) więc nie jestem żadnym ekspertem w temacie. Jednakże jedna rzecz nadzwyczaj mi się w nim spodobała i miałem nawet okazję ją ostatnio wykorzystać. Jest to jedna z wyróżniających cech tego języka czyli leniwa ewaluacja. Brzmi dość tajemniczo ale koncepcja jest bardzo prosta. Rozważmy prostą funkcję w C:
Leniwa ewaluacja spowoduje, że jeżeli akurat zmienna a będzie większa niż 100 to zmienna b nie zostanie w ogóle wyliczona. Zauważmy, że pod zmienną b może kryć się szereg wywołań funkcji ciężkich obliczeniowo. Wówczas nasz program będzie działał znacznie szybciej w Haskellu niż w C (napisany w ten sposób).
Niestety jak ktoś kiedyś napisał, leniwa ewaluacja to nie święty graal programowania, to coś z czym trzeba nauczyć się żyć. Powoduje ona masę problemów związanych z przepełnieniem stosu. Chodzi o to, że żadna zmienna nie jest wyliczana od razu lecz dopiero w momencie gdy zostaje użyta. Zamiast jej wartości odkładany na stos jest adres do instrukcji, które pozwalają ją wyliczyć. Jeśli więc np. funkcja działa rekurencyjnie to może takich adresów sporo odłożyć i dochodzi wówczas do przepełnienia stosu.
Leniwa ewaluacja pozwala jeszcze na jedną rzecz. Mianowicie na definiowanie w programie typów nieskończonych oraz operacji na nich. W Haskellu zatem możliwe jest zapisanie listy wszystkich liczb naturalnych:
Weź pierwszy element (head) z listy powstałej z wyrażenia ($) różnicy (//) liczb naturalnych ([0..]) i listy (lista).
Wygląda to bardzo zwięźle i czytelnie a do tego nie musimy się martwić o warunki do sprawdzenia ani o zakres liczb do przeszukania. Podsumowując warto się zainteresować językami z leniwą ewaluacją lecz trzeba jej używać z głową :)
int check(int a, int b) {
if (a > 100)
return 100;
if (a > b)
return b;
return a;
}
Leniwa ewaluacja spowoduje, że jeżeli akurat zmienna a będzie większa niż 100 to zmienna b nie zostanie w ogóle wyliczona. Zauważmy, że pod zmienną b może kryć się szereg wywołań funkcji ciężkich obliczeniowo. Wówczas nasz program będzie działał znacznie szybciej w Haskellu niż w C (napisany w ten sposób).
Niestety jak ktoś kiedyś napisał, leniwa ewaluacja to nie święty graal programowania, to coś z czym trzeba nauczyć się żyć. Powoduje ona masę problemów związanych z przepełnieniem stosu. Chodzi o to, że żadna zmienna nie jest wyliczana od razu lecz dopiero w momencie gdy zostaje użyta. Zamiast jej wartości odkładany na stos jest adres do instrukcji, które pozwalają ją wyliczyć. Jeśli więc np. funkcja działa rekurencyjnie to może takich adresów sporo odłożyć i dochodzi wówczas do przepełnienia stosu.
Leniwa ewaluacja pozwala jeszcze na jedną rzecz. Mianowicie na definiowanie w programie typów nieskończonych oraz operacji na nich. W Haskellu zatem możliwe jest zapisanie listy wszystkich liczb naturalnych:
[0..]Odbywa się to w ten sam sposób jak powyżej. Dopóki nie żaden element z listy nie jest potrzebny to pamiętany jest tylko adres jak wyliczyć kolejny element listy. Oczywiście próba wypisania wszystkich elementów tej listy skończy się w końcu brakiem pamięci. Podam teraz przykład kiedy się to może przydać. Załóżmy, że mamy jakąś (skończoną) listę liczb i chcielibyśmy poznać najmniejszą liczbę naturalną, która nie należy do tej listy (ten problem występuje np. w zagadnieniach kolorowania grafu). W imperatywnym języku musielibyśmy pisać pętle z szeregiem instrukcji warunkowych, które strasznie zaciemniają istotę tego co robimy. Jak zatem wygląda to w Haskellu? A tak:
head $ [0..] // listaTe dwa ukośniki (//) to nie żaden komentarz tylko operator usuwający elementy z pierwszej listy (po lewej), które występują w drugiej (po prawej). Przeczytajmy więc to wyrażenie od lewej strony:
Weź pierwszy element (head) z listy powstałej z wyrażenia ($) różnicy (//) liczb naturalnych ([0..]) i listy (lista).
Wygląda to bardzo zwięźle i czytelnie a do tego nie musimy się martwić o warunki do sprawdzenia ani o zakres liczb do przeszukania. Podsumowując warto się zainteresować językami z leniwą ewaluacją lecz trzeba jej używać z głową :)
wtorek, 8 listopada 2011
Zagrajmy w golfa!
Serwis zawiera kilkadziesiąt zadań do wykonania. Zadania polegają na przekształceniu pliku wejściowego tak aby przy użyciu najmniejszej liczby naciśnięć klawiszy uzyskać plik wyjściowy. Jednakże by w ogóle móc się z kimś porównać należałoby mieć tą samą wersję Vima, te same pluginy i te same ustawienia. Nie musisz się o to martwić, autor strony o wszystkim pomyślał.
Aby w ogóle móc brać udział w zabawie należy zarejestrować się na stronie przy użyciu Twittera. Jeżeli więc nie masz konta to musisz je sobie założyć. Gdy się zarejestrujemy uzyskamy klucz (VimGolf key). Później należy zainstalować sobie skrypt napisany przez autora w Rubym za pomocą polecenia:
$ gem install vimgolf
Jeżeli wszystko przejdzie pomyślnie to w dalszym ciągu uruchamiamy polecenie:
$ vimgolf setup
Program zapyta nas o klucz, który uzyskaliśmy rejestrując się na stronie.
Na koniec pozostaje nam wybrać sobie zadanie i wykonać polecenie:
$ vimgolf put [challenge ID]
gdzie [challenge ID] jest podane na stronie z zadaniem. Po wykonaniu powyższego polecenia uruchomi się nam Vim z załadowanym plikiem wejściowym i spełniający wszystkie kryteria, które opisałem w poprzednim akapicie. Dokonujemy w nim niezbędnych zmian i wychodzimy z Vima uprzednio zapisując plik. Skrypt zliczy nasze wciśnięcia klawiszy i zapyta się czy wysłać wynik na serwer.
To wszystko. Zatem do dzieła!
piątek, 4 listopada 2011
Makra w Vimie

Tworzenie makr
Nagrywanie makra rozpoczynamy wciskając q oraz literę (a-z). Oznacza ona nazwę rejestru, do którego będą zapisywane wciskane klawisze. Ta informacja przyda nam się później do przypisywania skrótu klawiszowego. Gdy już rozpoczniemy nagrywanie to wykonujemy kolejno czynności, które chcielibyśmy powtarzać, a później kończymy nagrywanie wciskając klawisz q. W tym momencie możemy wykonać makro wciskając @ oraz literę, którą wybraliśmy przy nagrywaniu makra.
Podam teraz przykład bardzo prostego makra. Będzie ono wstawiać zaznaczony tekst w cudzysłowy, czyli jak zaznaczymy tekst Ala ma kota. i wykonamy makro to w efekcie dostaniemy "Ala ma kota.".
Cały trik polega na tym, że wycinamy zaznaczony tekst, wstawiamy cudzysłów, wklejamy tekst i wstawiamy cudzysłów. Wykonujemy więc kolejno:
1. zaznaczamy kawałek tekstu
2. rozpoczynamy nagrywanie makra "a": qa
3. wycinamy tekst: c
4. wstawiamy cudzysłów: "
5. wychodzimy z trybu wstawiania:
6. wklejamy wycięty tekst: p
7. przechodzimy do trybu wstawiania: a
8. wstawiamy cudzysłów: "
9. wychodzimy z trybu wstawiania:
10. kończymy nagrywanie makra: q
Teraz możemy przetestować działanie naszego makra poprzez zaznaczenie dowolnego tekstu i wciśnięcie @a.
Przypisanie skrótu klawiszowego
Skróty tworzy się poleceniem map. Jego składnia z grubsza wygląda tak:
:map <klawisz> <sekwencja>
Aby więc zmapować jakieś makro potrzebujemy nagranej sekwencji. Jak już wspominałem wcześniej makra zostają zapisane do wybranego rejestru, tzn. jeżeli na początku wcisnęliśmy qa to nasza sekwencja znajduje się w rejestrze a. Możemy więc w bardzo prosty sposób ją wyciągnąć. Mianowicie jak już wpiszemy np. :map <C-t> to wciskamy <C-r> po czym naciskamy literę odpowiedniego rejestru czyli w naszym przypadku jest to a. Sekwencja w ten sposób zostanie wklejona po czym pozostaje nam tylko zatwierdzić wciskając enter.
Zapisanie skrótu na stałe
Każde wykonane polecenie map jest pamiętane jedynie dopóki nie zamkniemy Vima. Aby temu zapobiec musimy dopisać wywołanie tego polecenia w pliku .vimrc. W tym celu otwieramy ów plik i dopisujemy:
map <skrót> <sekwencja>
Jeżeli chcemy wkleić zawartość rejestru a do treści pliku to wystarczy poprzedzić komendę p kombinacją "<litera_rejestru> czyli w naszym wypadku wciskamy "ap.
Nasza linijka powinna wyglądać mniej więcej tak:
map <C-t> c" ^]pa"^]
Na koniec kilka uwag:
- Skrót <C-t> oznacza przytrzymanie przycisku Ctrl oraz wciśnięcie klawisza t,
- Aby podejrzeć zawartość rejestrów bez wklejania można wywołać polecenie :registers,
- Skrót <C-r> służący do wklejania zawartości rejestrów (i nie tylko ale o tym może innym razem) można wywołać także w trybie wprowadzania,
- Do powtarzania tylko ostatniej czynność możemy użyć klawisza . (kropka) zamiast nagrywania makra, np. gdy chcemy po prostu wstawić jakiś tekst parę razy to wstawiamy go raz a potem . (kropka) będzie robić to za nas.
Zachęcam wszystkich do radosnego tworzenia własnych makr!
środa, 2 listopada 2011
Vim - ciekawsze pluginy
Jako, że na co dzień używam Vima w pracy i w domu to zdążyłem już wyrobić sobie opinie na temat różnych pluginów. Najciekawsze i jednocześnie najczęściej przeze mnie korzystane omówię poniżej:
- Conque Shell
Wtyczka, która czyni z Vima terminal. Najlepiej omówić to na przykładzie. Ja używałem bardzo często tego pluginu do integracji z klientem MySQLa, tzn. dzięki Conque Shell uruchamiamy z Vima wybrany program a jego wyjście pojawi się nam w oknie. Na tym co wyświetli program będziemy mogli operować tak jak na każdym pliku tekstowym. Co więcej, w trybie wprowadzania komunikujemy się z programem. W moim przypadku bardzo często przeklejałem całe SQLe i wyświetlał mi się wynik w postaci ładnej tabelki wewnątrz Vima.
Tutaj widać 3 uruchomione procesy wewnątrz Vima (bash,top,ipython):

Obsługa:
- :ConqueTermSplit
Powoduje uruchomienie procesu w oknie poniżej. - :ConqueTermVSplit
Powoduje uruchomienie procesu w oknie z lewej. - <F9>
Przekleja zaznaczony tekst do procesu ostatnio uruchomionego.
Przykład: :ConqueTermSplit bash - :ConqueTermSplit
- vcscommand
Bardzo fajny skrypt do integracji z wieloma systemami kontroli wersji (konkretnie CVS, SVN, SVK, git, bzr, hg). Sprawia on, że edytując dany plik nie musimy się zastanawiać czy aby zobaczyć jego historię musimy wywołać svn log czy git log, gdyż ten skrypt sam to sprawdzi i wywoła za nas. Oczywiście posiada on znacznie więcej opcji, chociażby wyświetlanie zmian za pomocą mechanizmu Vima (:VCSVimDiff <commit>).
Obsługa:
- :VCSUpdate
Odpowiada komendzie svn update. - :VCSCommit
Otwiera okno na wpisanie komentarza. Po zamknięciu okna następuje commit. - :VCSDiff <commit>
Wypisuje zmiany aktualnej wersji w stosunku do podanej w argumencie w taki sam sposób jak svn diff (czy tam git diff itp.). - :VCSVimDiff <commit>
Tak samo jak powyżej tyle, że zmiany są wyświetlana za pomocą wewnętrznego mechanizmu Vima. - inne analogiczne polecenia takie jak: VCSLog, VCSBlame itd.
- :VCSUpdate
- The NERD tree
Nieco ciekawszy plugin do poruszania się po katalogach i plikach. Od razu dodam, bo może nie każdy wie, że próbując otworzyć katalog do edycji w Vimie wyświetla się nam jego skład i możemy się po nim poruszać, np. :e .
Ten plugin oferuje nam dodatkowe możliwości jak np. zakładki, tworzenie i usuwanie plików oraz katalogów, filtrowanie zawartości katalogów, sortowanie itd.
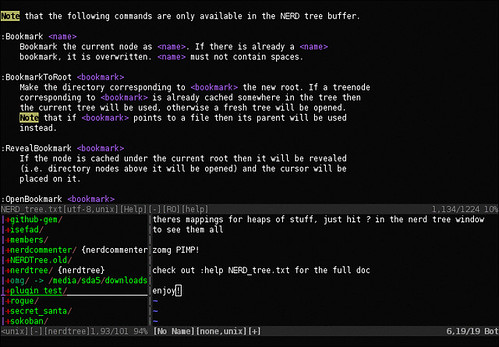
O obsłudze nie będę pisał, ponieważ ten plugin podmienia standardową funkcjonalność listowania katalogu. O reszcie można poczytać w pomocy.
- grep
Prosty skrypt służący do grepowania (wyszukiwania) po plikach. Wywołuje on program grep z różnymi opcjami rozszerzając jego funkcjonalność o filtry. Tym właśnie różni się on od wbudowanego polecenia vimgrep.
Podstawowa obsługa:
- :Grep <ciąg_do_wyszukania> <pliki>
Wyszukuje w danym katalogu. Jako <pliki> można wstawić *
- :RGrep <ciąg_do_wyszukania> <pliki>
Tak samo tylko, że wyszukuje również w podkatalogach.
- Filtry czyli w jakich plikach nie ma wyszukiwać można ustawić w pliku .vimrc:
let Grep_Skip_Dirs = '.svn CVS'
let Grep_Skip_Files = '*.bak *~ *.swp tags *.vim'
- :Grep <ciąg_do_wyszukania> <pliki>
- SQLUtilities
Fajna wtyczka do formatowania zapytań. Oczywiście potrafi ona znacznie więcej ale w gruncie rzeczy formatowanie jest najciekawsze i najbardziej przydatne.
Podstawowa obsługa:
- \sfs
Powoduje, że zaznaczony kod SQL zostaje ładnie sformatowany.
- \sfs
- comments
Również bardzo prosty skrypt do komentowania kodu. Rozpoznaje on automatycznie typ pliku i komentuje używając odpowiednich dla pliku symboli.
Obsługa:
- <Ctrl-C>
Komentuje linię bądź zaznaczenie. - <Ctrl-X>
Odkomentowuje linię bądź zaznaczenie.
- <Ctrl-C>
- TagBar
Fantastyczny plugin wyświetlający nam listę funkcji, klas, typów itp. w bocznym panelu.

Obsługa:
- <F9>
Wyświetla bądź chowa panel boczny.
- <F9>
- neocomplcache
Kolejny świetny skrypt. Umożliwia on podpowiadania "w locie" przy pisaniu jak obserwujemy w różnych edytorach. Ten plugin naprawdę polecam!

Co do obsługi to nie będę się również rozpisywał, najlepiej ze strony skryptu przekopiować domyślne ustawienia do pliku .vimrc i potestować.
Subskrybuj:
Posty (Atom)